CatBoostでランク学習をしてみる

競馬で的中率・回収率を上げるために自作で予想AIを作り初めて早1年。
予想モデルはLightGBMのlambdalankを使っていますが、単勝回収率が80%を超えた辺りで現在頭打ちで、100%を超えられない現状です。馬券投資生活、夢のまた夢です。「釣りをしていても競馬で稼ぐ」が目標です(笑)
現在の予想モデルは、前日予想をするためにオッズや人気を特徴量に入れないでやってますが、ノイズかもしれませんが、結構面白い穴馬を指定することもあって満足はしているんですが、単勝回収率80%の壁が結構高くこのままだとジリ貧なので、何か改善できないものかと・・・
そこでアンサンブルとして、同じGBDTのCatBoostを使ってみようと思い立ちました。
最初のきっかけはCatBoostはGPUでの計算が簡単に出来るという理由でした。
というのも、NVIDIAの GeForce RTX2070を使っているのですが、まるっきり活かせてなくて。
Deep Learningのベースにある機械学習という分野を軽視していたせいです。
Deepを勉強するためにはGPUが必須と早とちりしてしまい、機械学習のことを全く考えていませんでした。
機械学習、GPUがなくてもCPUだけでも十分動かすこと出来るんですね。
データは競馬5年分を使ってますが10分あればすべての処理が終わってしまうくらいです。
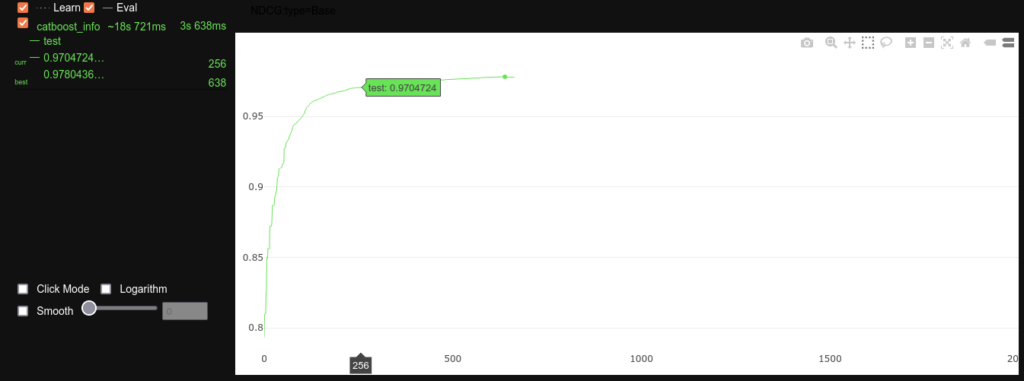
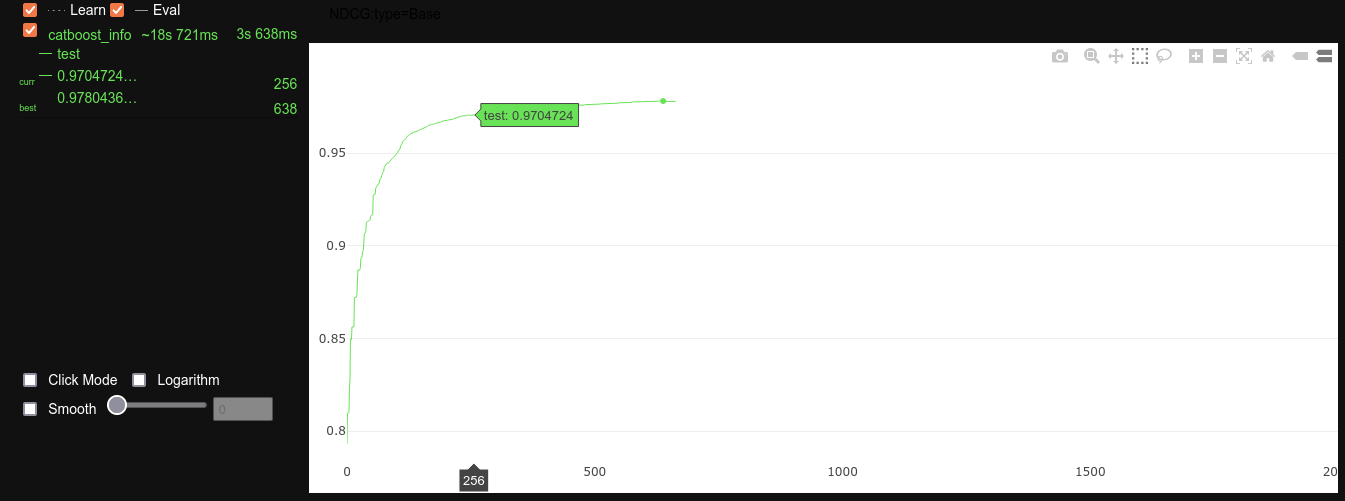
CatBoostの学習経過
予想モデルはLightGBMのlambdalankを使っていますが、単勝回収率が80%を超えた辺りで現在頭打ちで、100%を超えられない現状です。馬券投資生活、夢のまた夢です。「釣りをしていても競馬で稼ぐ」が目標です(笑)
現在の予想モデルは、前日予想をするためにオッズや人気を特徴量に入れないでやってますが、ノイズかもしれませんが、結構面白い穴馬を指定することもあって満足はしているんですが、単勝回収率80%の壁が結構高くこのままだとジリ貧なので、何か改善できないものかと・・・
そこでアンサンブルとして、同じGBDTのCatBoostを使ってみようと思い立ちました。
最初のきっかけはCatBoostはGPUでの計算が簡単に出来るという理由でした。
というのも、NVIDIAの GeForce RTX2070を使っているのですが、まるっきり活かせてなくて。
Deep Learningのベースにある機械学習という分野を軽視していたせいです。
Deepを勉強するためにはGPUが必須と早とちりしてしまい、機械学習のことを全く考えていませんでした。
機械学習、GPUがなくてもCPUだけでも十分動かすこと出来るんですね。
データは競馬5年分を使ってますが10分あればすべての処理が終わってしまうくらいです。
参考
- CatBoost
- CatBoostのランク学習(Learning to rank)をためそう
- GBDT系の機械学習モデルのパラメータチューニング奮闘記 ~ CatBoost vs LightGBM vs XGBoost vs Random Forests ~ その1
CatBoost
学習部分のプログラムはLightGBMで作った特徴量をほぼそのまま流用できて、意外と簡単でした。LightGBMと違ったところ
- CatBoostはCategory変数のインデックス番号を指定する必要がある【*1】
- データセットの作成にPool()を使う【*2】
- ‘loss_function’:’YetiRank’ CatBoostでランキング学習する時はYetiRankを指定【*3】
- パラメータに ‘task_type’: ‘GPU’ と指定するだけでGPUで計算してくれる 【*4】
使い方(必要ならpip installでインストール)
# pipenv install catboost (pipenvで管理してるので) from catboost import CatBoost from catboost import Pool
学習部分
# category変数をインデックス番号で指定
cat_features = [0, 13, 14, 19, 20, 29, 31, 32] # 【*1】
# CatBoost が扱うデータセットの形式に変換 【*2】
train_pool = Pool(data=X_train, label=y_train, group_id=train_group_id, cat_features=cat_features)
valid_pool = Pool(data=X_valid, label=y_valid, group_id=valid_group_id, cat_features=cat_features)
param = {
'loss_function':'YetiRank', # YetiRankはpairwiseでのランク学習の1つ 【*3】
'learning_rate': 0.05,
'l2_leaf_reg': 8,
'iterations': 1000,
'depth': 7, # YetiRank では MAX 8
'use_best_model': True,
'early_stopping_rounds': 25, # アーリーストッピング
'has_time': True,
'task_type': 'GPU', # GPUを使う 【*4】
}
model = CatBoost(param)
model.fit(train_pool, eval_set=valid_pool, verbose_eval=100, plot=True) # 経過を表示しない時 verbose=False
feature_importances = model.get_feature_importance(train_pool)
feature_names = X_train.columns学習経過など見たい時
# CatBoost グラフ ダート
fti = pd.Series(feature_importances_catdart, index=feature_names_catdart)
fti.plot(kind='barh', figsize=(15, 8))
# 重要度出力
#for score, name in sorted(zip(feature_importances, feature_names), reverse=True):
# print('{}: {}'.format(name, score))
model.fit()にplot=Trueを指定したら学習経過がグラフで見れるので面白いです。