Apache SparkをRaspberry Pi3やJetson nanoにインストール
機器情報など
- Raspberry Pi3 B+ PRETTY_NAME=”Raspbian GNU/Linux 11 (bullseye)”
- Jetson nano Ubuntu 18.04.6 LTS (Bionic Beaver)
ラズパイ3台、Jetson nano1台の計4台で分散コンピューティングしてみようかと思います。
マスターをラズパイより1台ピックアップし、残り3台をワーカーで設定してみます。
- マスター:rasp12
- ワーカー:rasp11, rasp13, jnano21
/etc/hostsファイルに記述してるんですが、上記のようにマスターとワーカーを分けることにしました。
(成り行きで変な分け方になってしまいました・・・)
前準備
(Jetson Nanoのみ) jdkのインストール
Sparkを動かすにはJavaが必要とのことで、インストールします。
(ラズビアンはプレインストールされてるみたいで必要ないです。)
$ sudo apt-add-repository ppa:openjdk-r/ppa
$ sudo apt update
$ sudo apt install openjdk-8-jdk /etc/hostsファイルへ追加
アクセスしやすくするために別名を付けました。
192.168.0.212 rasp12
192.168.0.211 rasp11
192.168.0.213 rasp13
192.168.0.221 jnano21sparkユーザの追加
作業はsparkユーザを作ってやるのが好みだったので、追加しました。
$ sudo adduser spark
$ su - sparkここからのの作業はsparkユーザでの作業になります。
Apache Sparkのダウンロード&解凍(4台)
4台全てに同じ作業をします。
作業用ディレクトリの作成
マスター、ワーカーで同じパスに置いておくと良いという事で、作業ディレクトリをそれぞれ作ります。
ユーザのルートにSparkディレクトリを作成して、この中にApache Sparkの本体を置くことにします。
/optとか/usr/localとかに移そうかとも思ったのですが、面倒だったのでこのまま作業しました。
$ mkdir Spark
$ cd Spark
$ pwd ## /home/spark/Spark
ダウンロード
ダウンロードして解凍したディレクトリ名をspark-3.2と変更しました。ここら辺はお好みでしょうか。
Apache Sparkのダウンロードページからたどっていってダウンロードしますが、最新版が3.2.0だったのでこれを選択しました。
$ wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
$ tar zxvf spark-3.2.0-bin-hadoop3.2.tgz
$ mv spark-3.2.0-bin-hadoop3.2 spark-3.2
$ cd spark-3.2
マスターの起動(rasp12)
マスターに設定するrasp12での作業になります。
$ pwd ## /home/spark/Spark/spark-3.2
$ sbin/start-master.sh -h rasp12ワーカーの起動方法(rasp11, rasp13, jnano21)
ワーカーに設定するrasp11, rasp13, jnano21での作業になります。
以下の1, 2のどちらかで起動します。
1. リソースに制限をかけない場合
$ pwd ## /home/spark/Spark/spark-3.2
$ sbin/start-worker.sh spark://rasp11:70772. リソースを制限する場合
この場合はCPUを1コア, メモリを2GBに設定
$ pwd ## /home/spark/Spark/spark-3.2
$ sbin/start-worker.sh spark://rasp13:7077 -c 1 -m 2Gちなみにマスターもワーカーとして登録可能なようです。
昔はスレーブって記述が多いみたいですが、今はワーカーと呼ぶみたいですね。slaveで起動しようとすると、「無効になった」とかで怒られました。
This script is deprecated, use start-worker.sh
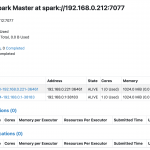
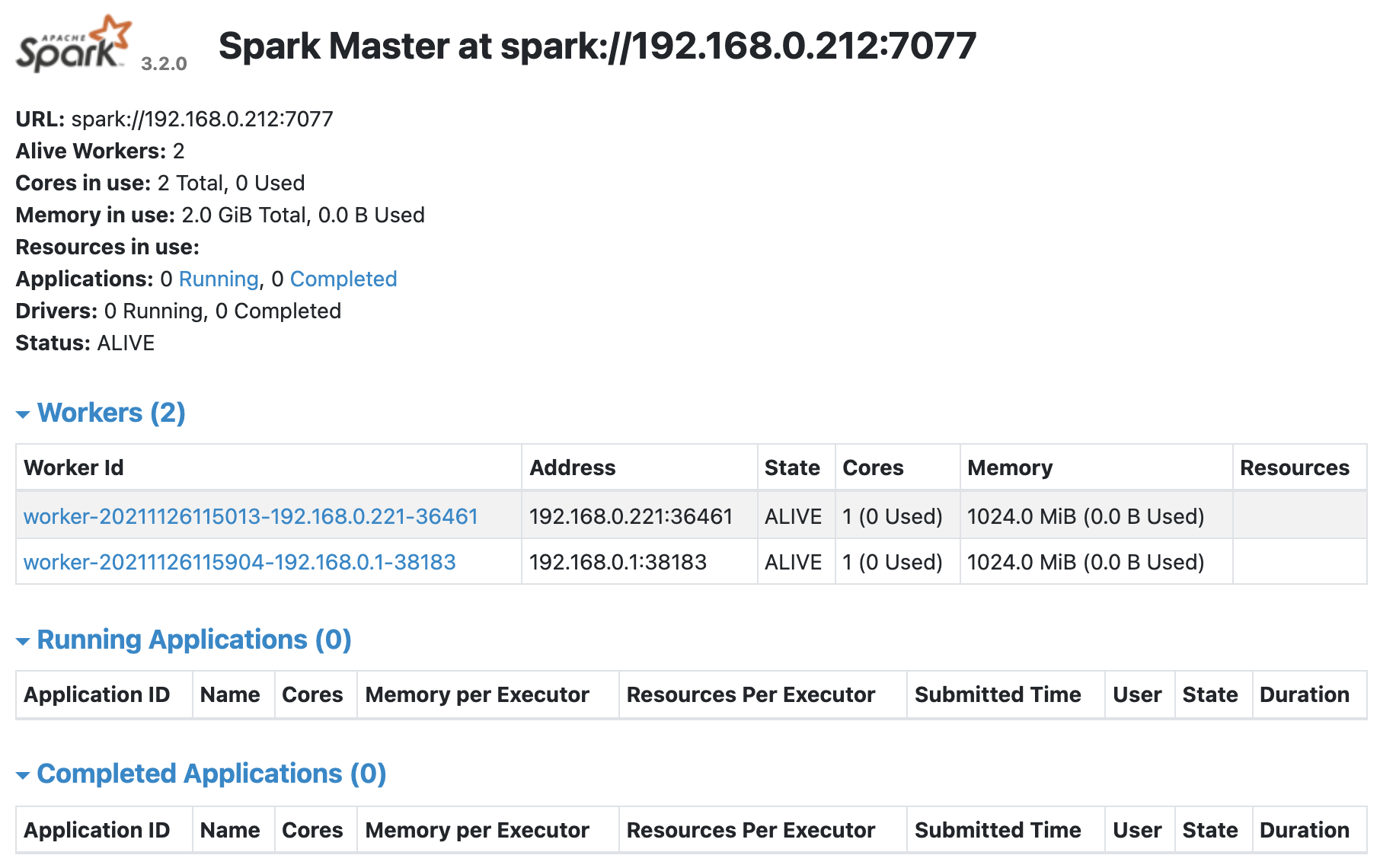
クラスタ起動を確認
ブラウザで確認
以下のURLでアクセスして起動を確認できます。(画像はまだワーカーを2台しか起動していない状態です・・・)http://192.168.0.212:8080
pysparkで確認
$ bin/pyspark ## ワーニングが出るがとりあえず動いてるようです
>>> sc.parallelize(range(10000)).collect()
>>> exit()
停止方法
ワーカー(それぞれのコンピューターで実行)
$ sbin/stop-worker.shマスター
$ sbin/stop-master.shサンプルで確認してみる
こちらを参考にちょっと動かしてみようと思います。
マスターに接続
URLにマスターに設定したアドレスを指定します。マスターのWeb画面のURLの項目で確認できます。
bin/pyspark --master spark://192.168.0.212:7077Sparkのロゴとメッセージが流れ、プロンプトが >>> に変わります。Webページを見るとRunning Applicationsにタスクが増えています。

@ITさんのサンプルはScalaのようなので、これをPythonに変換して実行してみようと思います。Scalaは分からないので ChatGPTに変換してもらいました。
sc.parallelize(1 to 1001, 8).map(_*2).reduce(_+_)
Pythonではこうなるようです。
from pyspark import SparkContext
# SparkContextを作成
sc = SparkContext("local", "MyApp")
# 1から1000までの整数のリストを作成
data = list(range(1, 1001))
# リストをRDDに変換
rdd = sc.parallelize(data, 10)
# 各要素を2倍にマップ
mapped_rdd = rdd.map(lambda x: x * 2)
# 要素を合計
result = mapped_rdd.reduce(lambda x, y: x + y)
# 結果を出力
print(result)
# SparkContextを停止
sc.stop()これを実行してみます。>>> の後に追加しました。とりあえず一行で済ませてます。
data = list(range(1, 1001));rdd = sc.parallelize(data, 8);mapped_rdd = rdd.map(lambda x: x * 2);result = mapped_rdd.reduce(lambda x, y: x + y);print(result);1001000 を確認できました。
Pythonファイルを読み込んで実行
通常はファイルに書いたPythonコードから実行したいところです。bin/spark-submitとというコマンドを使い、例としてtest_script.pyというファイルを実行しています。
bin/spark-submit test_script.py --master spark://192.168.1.251:7077とりあえずここまで
数年前にApache Sparkの存在を知った時は、インストールはすごく面倒で難しく感じたのですが、ネットの色々な情報のおかげでなんとか設定することができました。感謝いたします。
以上になります。またお会いしましょう